
Understanding Decision Tree Algorithm
Decision Tree Algorithm for Machine Learning
Hello Everyone,
Welcome to my blog, In this blog, we are going to discuss one of the Machine Learning algorithms which is the Decision Tree Algorithm. This Algorithm is very easy to understand and use. It is an algorithm that can be used for classification and regression problems. So let us start our journey of learning this algorithm.
These are the topics that we will cover in this article:-
- What is a Decision Tree?.
- Decision Tree Algorithm Steps.
- Decision for Classification / Regression
- How can we select the best attribute for the root node
- Hyperparameters In the Decision Tree.
- Advantages and Disadvantages of Decision Tree
- Applications Of Decision Tree
What is a Decision Tree?
The decision tree algorithm is a supervised machine learning algorithm, which can be used for classification as well as regression problems. As per the name, we can get an idea that it is a Tree with some decisions made. In a Normal Tree, we see that there are various nodes like Root nodes and Leaf nodes.
Same in Decision Tree we have nodes such as:-
- Root node
- Decision node
- Leaf node
Root Node:- Root Node is Basically a Node present at the Start of any decision tree which is further divided according to various attributes.
Decision Node:- The nodes which are generated from the root node are known as Decision Nodes
Leaf Node:- Nodes that cannot be further divided are known as leaf nodes

Decision Tree Algorithm Steps
Step 1: Start with the root node, which holds the entire dataset, say D.
Step 2: Using the Attribute Selection Measure (ASM), we can search for the best attribute in the dataset.
Step 3: Subdivide the D into subsets that contain the best attribute's possible values.
Step 4: Create a node for the decision tree with the best attributes..
Step 5: Using the subsets of the dataset obtained in step 3, create further decision trees in a recursive way. Continue until the nodes can no longer be categorized, at which time the final node is called a leaf node
Decision Tree for Classification / Regression
The Decision Tree Algorithm is based on the Nested IF ELSE statement. When trying to predict a continuous output variable, regression is applied.
Classification, on the other hand, is used to determine which class a set of attributes should belong to.
It functions by dividing the data into smaller and smaller subgroups in a tree-like arrangement. When it comes to estimating the output value of a collection of attributes, it will do so based on which subset of the set of attributes it belongs to.
Decision trees are divided into two types:
Classification Tree:- When a dataset needs to be divided into classes that correspond to the response variable, classification trees are used.
Regression Tree:- When we need to predict the continuous values we use regression trees
How can we select the best attribute for the root node
So, to solve such problems we use the Attribute selection measure or ASM Technique. By this ASM, we can easily select the best attribute for the nodes of the tree. There are two techniques for ASM present, which are:
- Information Gain
- Gini Index
- The measure of entropy changes after segmenting a dataset based on its attributes is known as Information gain
Calculation of Information Gain
Information gain Formula is based on the entropy:-
- Information Gain = 1 – Entropy
- The decision tree algorithm always tries to maximize the value of the information gain, and the node/attribute with the highest information gain is split first, We can calculate the Entropy by the Following Formula given below.
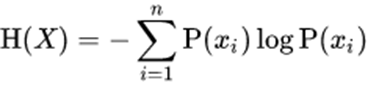
Where
X = random variable or process
Xi = possible outcomes
p(Xi) = probability of possible outcomes.
- The measure of impurity or purity used while creating a decision tree in the CART(Classification and Regression Tree) algorithm is called as Gini Index
- Attribute with a low Gini index is preferred as compared to a high Gini index.
- Gini Index= 1- ∑jPj2
Hyperparameters In the Decision Tree:-
1:- max_depth int, default=None:- The maximum depth of the tree. The more the value of max_depth, the more complex the tree gets.
2:- min_samples_split int or float, default=2:- Minimum number of samples required to split a node
3:- min_samples_leaf int or float, default=1:- Minimum number of samples required to be at a leaf node. The Possibility of overfitting will increase as you increase the number
Advantages of Decision Tree:-
1:- Decision Tree is Quite easy to learn and implement by other ML algorithms
2:- We can use it when we have to take decisions on decision-related problems
3:- Data Cleaning Process is Less compared to other algorithms
Disadvantages of Decision Tree:-
1:- It contains many layers of decisions that can be complex in nature
2:- One must ensure and be aware of choosing the root node or else the model can be built wrong
3:- It Can Overfit sometimes
Applications Of Decision Tree:-
- There might be various uses of the Decision Tree Algorithm in classification and Regression.
- Some Applications of it in various domains are as follows:-
- Healthcare Management
- Engineering
- Customer Relationship Management
But, Some Applications of the Decision Tree Algorithm are also seen in Machine Learning…!
Yes, In machine Learning there is an algorithm named Random Forest which is the extension of the Decision Tree Algorithm, where random forest uses several decision trees and takes their output to come up with the output of the Random Forest Algorithm.
- Malhar Jadhav
- Jun, 26 2022